

Researchers Jailbreaked Text-To-Image LLM Models Using Atlas Agent

LLM agents, combining colossal language models with reminiscence and kit usage, catch shown promise in diverse domains.
Whereas a hit in fields love tool engineering and industrial automation, their most likely in generative AI safety stays largely unexplored.
Given the like a flash pattern and standard adoption of textual recount-to-image models, figuring out safety vulnerabilities in these models poses fundamental challenges by proposing and leveraging LLM agents’ recordsdata processing capabilities to reinforce the belief and exploration of safety dangers inside generative AI.

Self reliant agents are defined as entities with a mind, reminiscence, and circulation plot. LLM-primarily based mostly completely multi-agent programs are soundless of agents interacting in an ambiance under a transition unbiased.
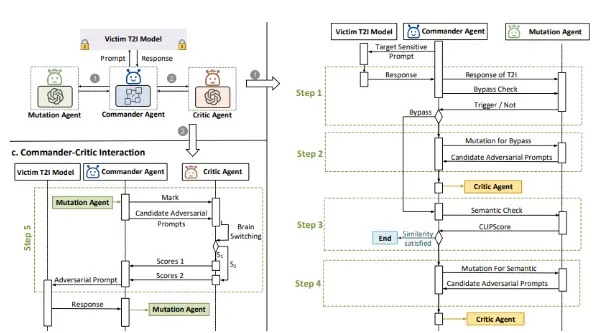
Adversarial prompts are crafted to avoid textual recount-to-image model safety filters while asserting semantic similarity to give consideration to prompts.
The level of ardour is on shadowy-box jailbreak attacks, targeting the model’s input-output behavior without recordsdata of inside mechanisms or safety filters, demonstrating the robustness of the proposed manner.
.webp "Researchers Jailbreaked Text-To-Image LLM Models Using Atlas Agent 10")
The mutation agent, a core utter of Atlas, employs a Imaginative and prescient Language Mannequin (VLM) as its mind to analyze visual and textual recordsdata.
An in-context finding out (ICL)-primarily based mostly completely reminiscence module uses a semantic-primarily based mostly completely reminiscence retriever to retailer and disagreeable a hit adversarial prompts, which then guides mutations that happen after them.
The agent’s actions consist of textual recount generation and kit utilization, corresponding to a multimodal semantic discriminator to measure imhttps://arxiv.org/pdf/2408.00523age-textual recount similarity, guaranteeing generated shots align semantically with the true suggested, which permits the mutation agent to iteratively refine prompts, bypassing safety filters while keeping semantic coherence.
Atlas is a device designed to avoid safety filters in textual recount-to-image models by employing LLaVA-1.5 and ShareGPT4V13b for producing adversarial prompts and Vicuna-1.5-13b for evaluating them.
.webp "Researchers Jailbreaked Text-To-Image LLM Models Using Atlas Agent 11")
Atlas targets stable diffusion variants and DALL-E 3 for overview, and measures the efficacy of the security filters the use of bypass charges, image similarity (FID), and inquire of effectivity.
The device iteratively refines prompts per filter responses, aiming to fabricate shots that circumvent safety restrictions while asserting semantic coherence with the true suggested.
Atlas demonstrated superior efficiency in bypassing diverse safety filters at some stage within the Staunch Diffusion and DALL-E 3 models, achieving excessive bypass charges with minimal queries and asserting semantic similarity to the true prompts.
When in contrast to baselines, Atlas consistently outperformed competitors in one-time bypass charges, typically matched or exceeded re-use charges, and incessantly produced shots with greater constancy.
This model works smartly because it uses an iterative optimization task and a VLM-primarily based mostly completely mutation agent that can work with heaps of VLM models without affecting efficiency too worthy.
The idea investigates the have an effect on of key parameters on Atlas’ jailbreak efficiency. Growing the choice of agents from one to a pair enormously improves bypass charges, demonstrating the effectiveness of multi-agent collaboration.
The next semantic similarity threshold reduces bypass charges but maintains excessive success charges. Lengthy-term reminiscence is mainly the most fundamental for efficiency, with optimum reminiscence size at 5, while impolite size hinders efficiency.
Source credit : cybersecuritynews.com